Privacy Policy
Projects
News
Company
Careers
Category
Year
Keyword
Topic
2024.03.29
PFN Launches “Omega Crafter” Video Game on Steam Today
Internship
2024.03.27
Call for Applications: PFN 2024 Summer Internship in Japan
News Release
2024.02.02
PFE to Develop 100B Multimodal Foundation Model and Test Pre-Training of 1T Large Language Model with NEDO’s Support
2024.01.18
Preferred Networks Releases CuPy v13
Event
PFN to showcase Omega Crafter at Taipei Game Show 2024
2023.12.05
PFN, IIJ and JAIST to Launch Joint Research Project on Ultra-High-Efficiency AI Computing Infrastructure
2023.11.10
PFN at SC23 International Conference for High Performance Computing
2023.11.01
PFN Establishes New Subsidiary Preferred Elements for Development and Sales of Multimodal Foundation Model
2023.10.16
PFN’s MN-Core Deep Learning Processor Now Powers AI-Accelerated Materials Simulator Matlantis
2023.09.28
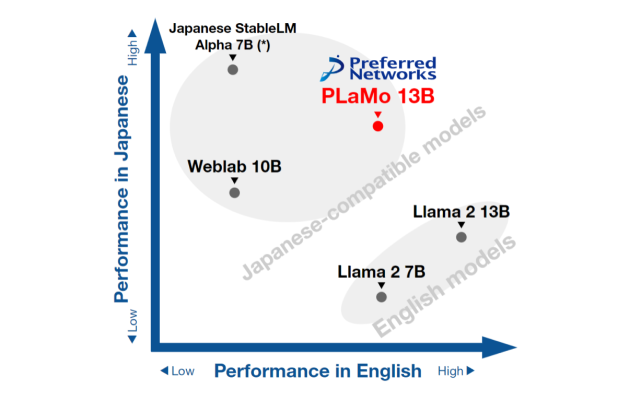
PFN Releases PLaMo-13B Open-Source Large Language Model in Japanese and English for Research and Commercial Use
2023.08.10
ENEOS and PFN Begin Continuous Operation of AI-Based Autonomous Petrochemical Plant System
2023.07.12
PFN to Showcase Omega Crafter at BitSummit Let’s GO!!
Contact us here.