Preferred Networks officially released ChainerMN version 1.0.0, a multi-node distributed learning package, making it even faster with stablized data-parallel core functions
Tokyo, Japan, September 1, 2017 – Preferred Networks, Inc. (PFN, Headquarters: Chiyoda-ku, Tokyo, President and CEO: Toru Nishikawa) has released the official version 1.0.0 of ChainerMN※1, which is a package adding distributed learning functionality with multiple GPUs to Chainer, the open source deep learning framework developed by PFN.
For practical application of machine learning and deep learning technologies, the ever-increasing complexity of neural network models, with a large number of parameters and much larger training datasets requires more and more computational power to train these models.
ChainerMN is a multi-node extension to Chainer that realizes large-scale distributed deep learning by high-speed communications both intra- and inter-node. PFN released the beta version of ChainerMN on May 9, 2017 and this is the first official release. The following features have been added to ChainerMN v1.0.0.
● Features of ChainerMN v1.0.0
1. Increased stability in core functions during data parallelization
With this improved stability, ChainerMN can be used more comfortably.
2. Compatibility with NVIDIA Collective Communications Library (NCCL) 2.0.
By supporting the latest version, it has become even faster.
3. More sample code (machine translation, DCGAN) is available.
These examples will help users learn more advanced ways of using ChainerMN.
4. Expansion of supported environments (non-CUDA-Aware MPI).
CUDA – Aware MPI implementation such as Open MPI and MVAPICH was necessary for the beta version, but ChainerMN is now compatible with non-CUDA-Aware MPI.
5. Initial implementation of model parallelism functions.
More complex distributed learning has become possible by getting multiple GPUs to work in the model parallelism method.
The conventional data parallelism approach is known to limit the possible batch size when increasing the nodes while maintaining accuracy. o overcome this, we have done the initial part of the more challenging implementation of model parallelism for greater speed than possible with data parallelism.
These features provide a more stable and faster than ever deep learning experiences with ChainerMN, as well as improved usability.
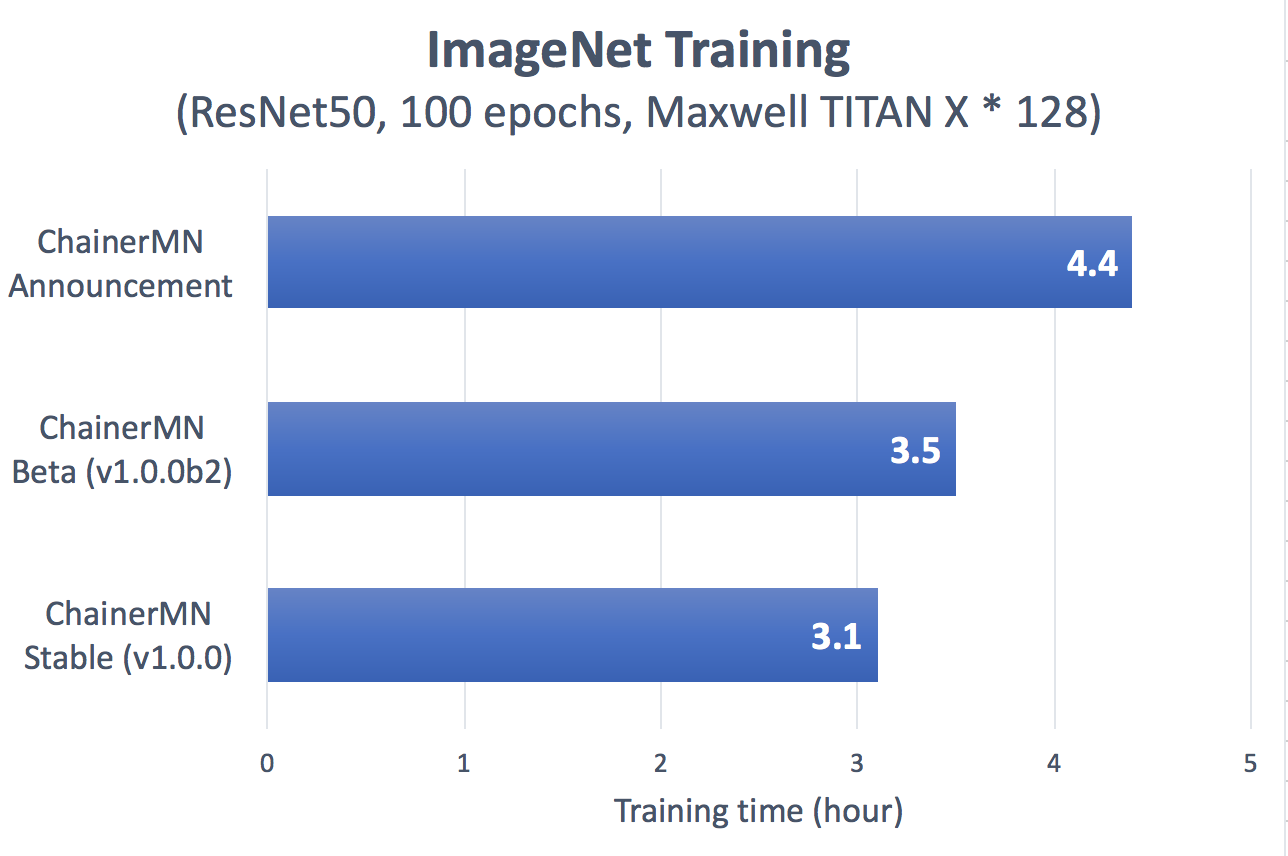
The following is the result of the performance measurement of ChainerMN using the image classification dataset of ImageNet. It is about 1.4 times faster than the first announcement in January this year, and 1.1 times faster than the beta version released in May. Please visit the following Chainer Blog to learn more about the experiment settings:
https://chainer.org/general/2017/02/08/Performance-of-Distributed-Deep-Learning-Using-ChainerMN.html
In addition, from October 2017, ChainerMN will become available on “XTREME DNA”, an unmanned cloud-based super-computer deployment and operation service, provided by XTREME Design Inc.(Head office: Shinagawa-ku, Tokyo, CEO: Naoki Shibata)
ChainerMN will be added on the distributed parallel environment templates for GPU instances of the pay-per-load public cloud, Microsoft Azure. This not only eliminates the need to construct infrastructure required for large-scale distributed deep learning but also makes it easy to manage research-and-development costs.
ChainerMN aims to provide an environment in which deep learning researchers and developers can easily concentrate on the main parts of research and development including the design of neural networks. PFN will continue to improve ChainerMN by adding more features and expanding its usage environment.
◆ The Open Source Deep Learning Framework Chainer (http://chainer.org)
Chainer is a Python-based deep learning framework developed by PFN, which has unique features and powerful performance that enables users to easily and intuitively design complex neural networks, thanks to its “Define-by-Run” approach. Since it was open-sourced in June 2015, as one of the most popular frameworks, Chainer has attracted not only the academic community but also many industrial users who need a flexible framework to harness the power of deep learning in their research and real-world applications.
※1:MN in ChainerMN stands for Multi-Node. https://github.com/pfnet/chainermn

